Advanced Azure Data Pipeline with Synapse Analytics.

Task Details
In this project, we will use Azure Data Lake Storage Gen2, SQL Server, and Azure Data Factory with managed identity, along with Synapse Serverless SQL, to securely store, process, and query data while enabling automated ETL and analytics workflows.
1. Create Azure Data Lake Storage Gen2 – Set up a central repository to store structured and unstructured data, forming the foundation of your data lake.
2. Create SQL Server and Database – Establish a relational data store to hold processed or curated data for structured queries and reporting.
3. Set up Azure Data Factory (ADF) – Implement an ETL/ELT orchestration service to move and transform data between systems automatically.
4. Enable System-Assigned Managed Identity on ADF – Configure secure, passwordless authentication for ADF to access other Azure resources.
5. Grant Permissions to ADF Managed Identity in Data Lake – Apply least-privilege access control so ADF can interact with the Data Lake securely.
6. Create Synapse Workspace with Serverless SQL Pool.
7. Query Data with Synapse SQL Serverless – Run serverless SQL queries on your data for analysis and reporting
*
Steps
Create Azure Data Lake Storage Gen2
1. Sign in to the Azure portal → Create a resource → Storage account.
2. Select StorageV2 (general-purpose v2).
In the Basic tab, fill out the following:

*
4. In Advanced tab
- Enable Hierarchical namespace (required for Data Lake Gen2).
Note: Use one container for all raw files to reduce management and costs.

*
5. In Networking tab
- Create virtual network name: Vnet01
- Create new subnet name: DataLakeSubnet
Note: In this project, I will allow public network access to the storage account for demonstration purposes. In a real-world scenario, this should be disabled to ensure proper security.

*
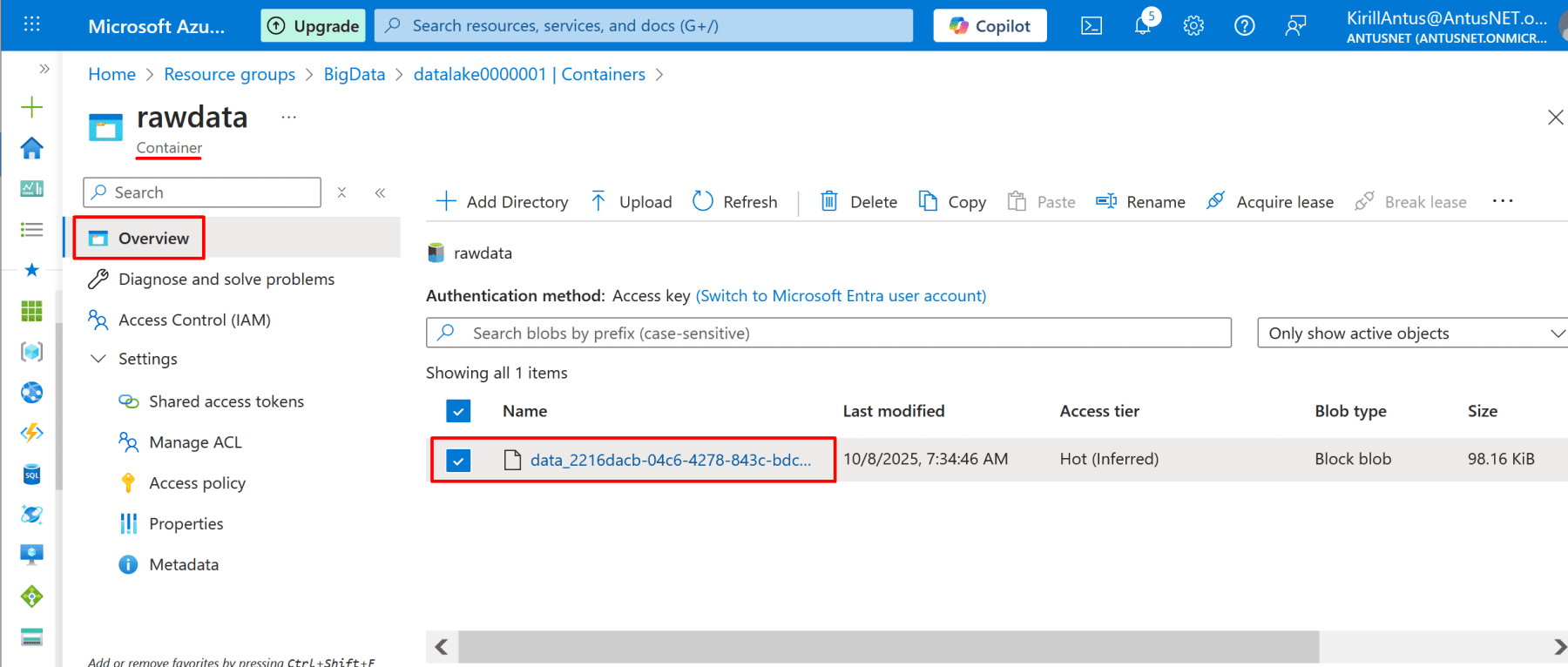
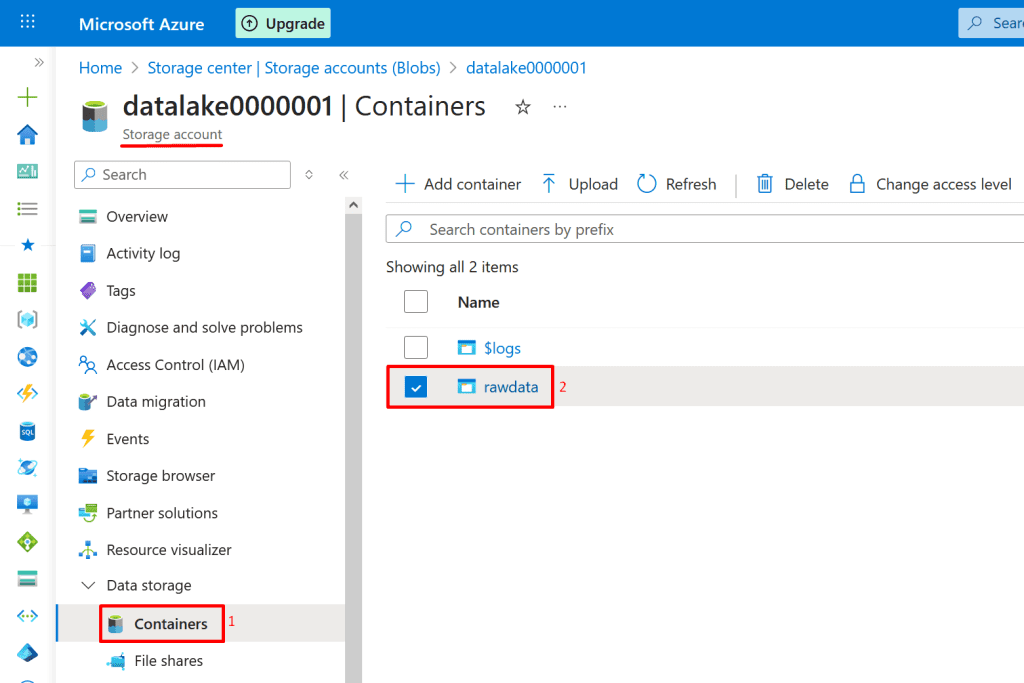
6. Once created, go to Containers → + Container → name it rawdata.
Note: Use one container for all raw files to reduce management and costs.


*
Create SQL Server and database
1. Please refer to the project Securing Azure SQL Database for detailed steps on setting up an Azure SQL Database and its associated server.
Note: In this example, we will use the pre-generated Sample database
Note: You will have to enable managed identity on SQL Server.

*
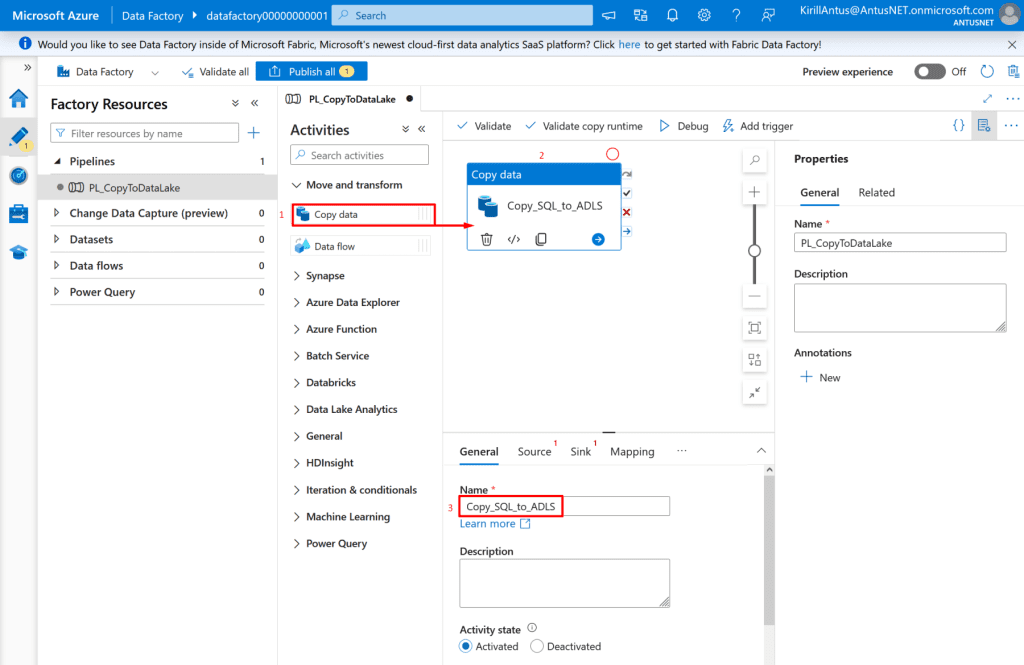
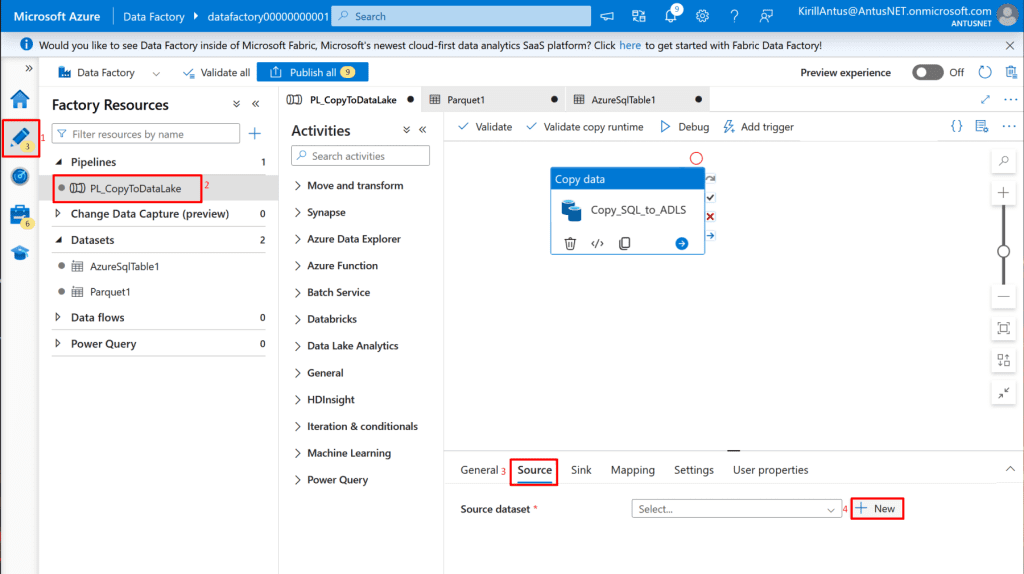
Create Azure Data Factory (ADF)
The purpose of Azure Data Factory (ADF) in this project is to act as the data movement and transformation engine, it automates how data flows between services like Data Lake Storage (ADLS Gen2) and SQL Database, and prepares it for Synapse Analytics to analyze.
1. Go to Create a resource → Data Factory → fill in name, region, and resource group then click Review+Create

*
Enable a system-assigned managed identity on Azure Data Factory
1. Go to your Data Factory in the Azure portal.
- In the left menu, select Managed Identities (under settings) → System assigned → Status: On → Save.
This will create a managed identity for your Data Factory.

*
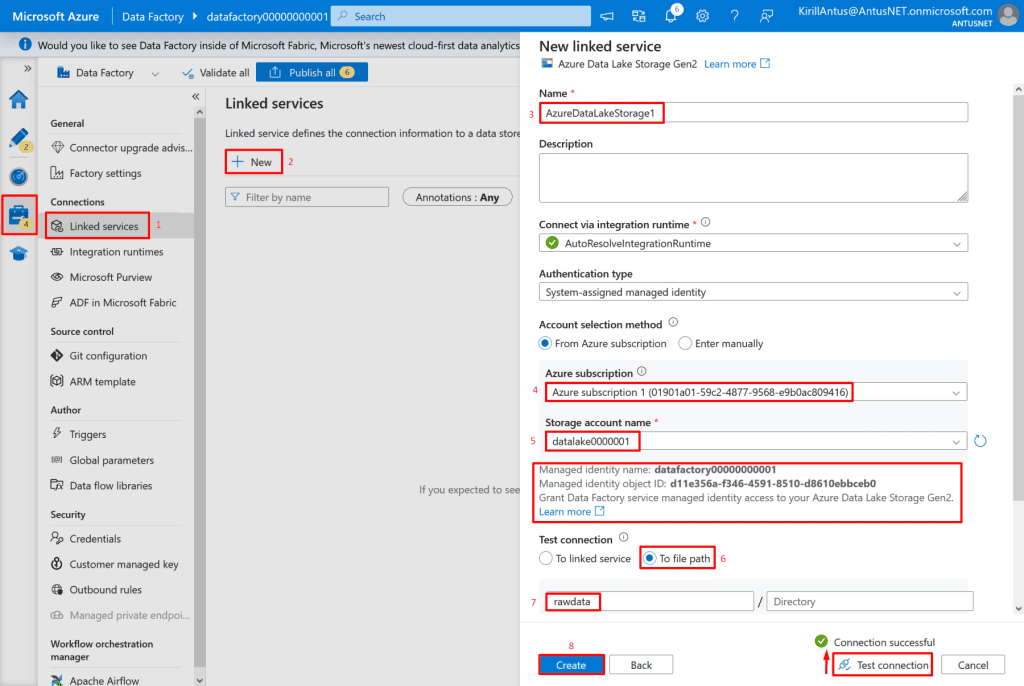
Grant the Data Factory managed identity permissions on the Data Lake Storage container ‘rawdata’
1. Go to your Storage Account → Data Lake Storage Gen2 container (rawdata).
*
2. Open Access Control (IAM) → click + Add role assignment.

*
3. Add Role: Storage Blob Data Contributor (allows read/write access).

*
4. Assign access to Data Factory’s managed identity → Select your Data Factory → Review + Assign.