End-to-End Azure Data Analytics Pipeline with Databricks, ADLS, and Synapse Analytics.

Task Details
In this project, you’ll create a secure, automated Azure data pipeline that ingests raw data into Azure Data Lake Storage Gen2 (ADLS), transforms it using Azure Databricks, and analyzes it through Azure Synapse Analytics Serverless SQL.
1. Create a Resource Group.
2. Create Azure Data Lake Storage Gen2.
3. Create an Azure Databricks Workspace.
4. Create and Configure Databricks Cluster and notebook.
5. Create Azure SQL Server & Database.
6. Create Azure Data Factory (ADF), configure its permissions, set up linked services, and perform data movement.
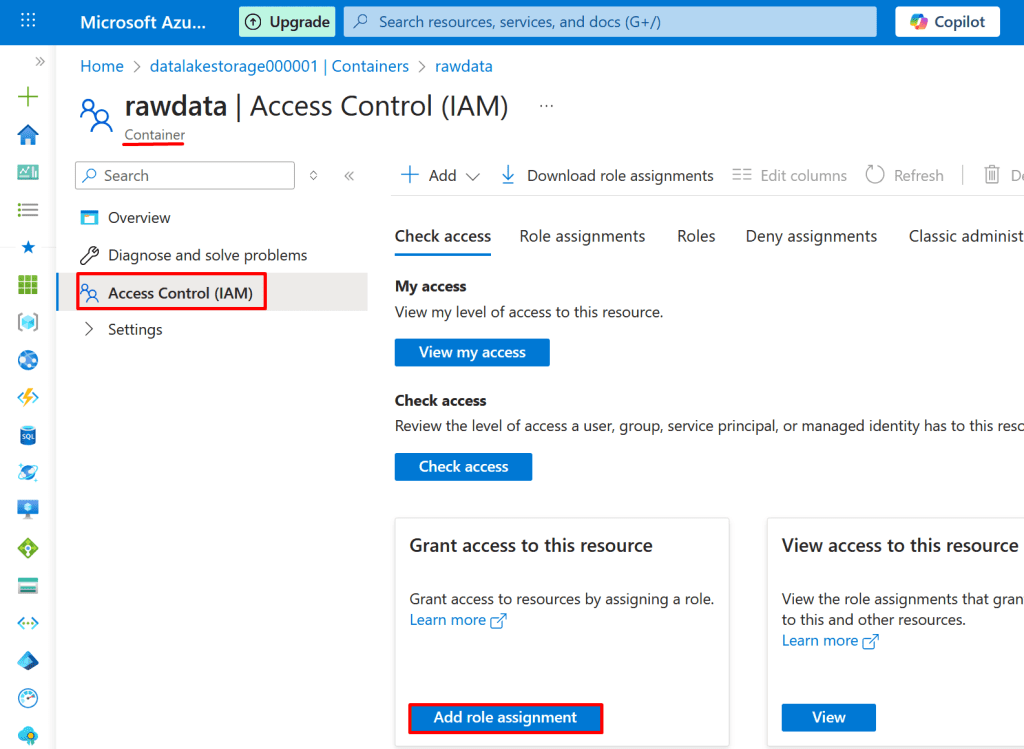
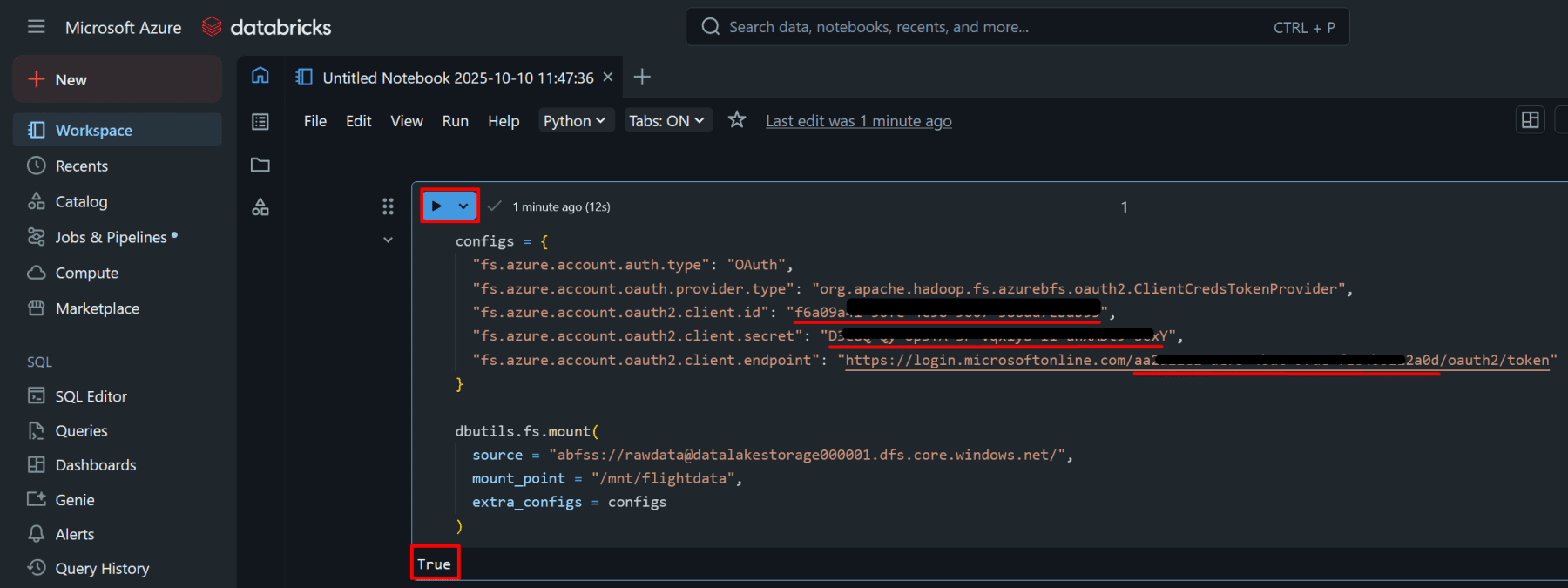
7. Configure Access for Databricks Using Client Credentials OAuth.
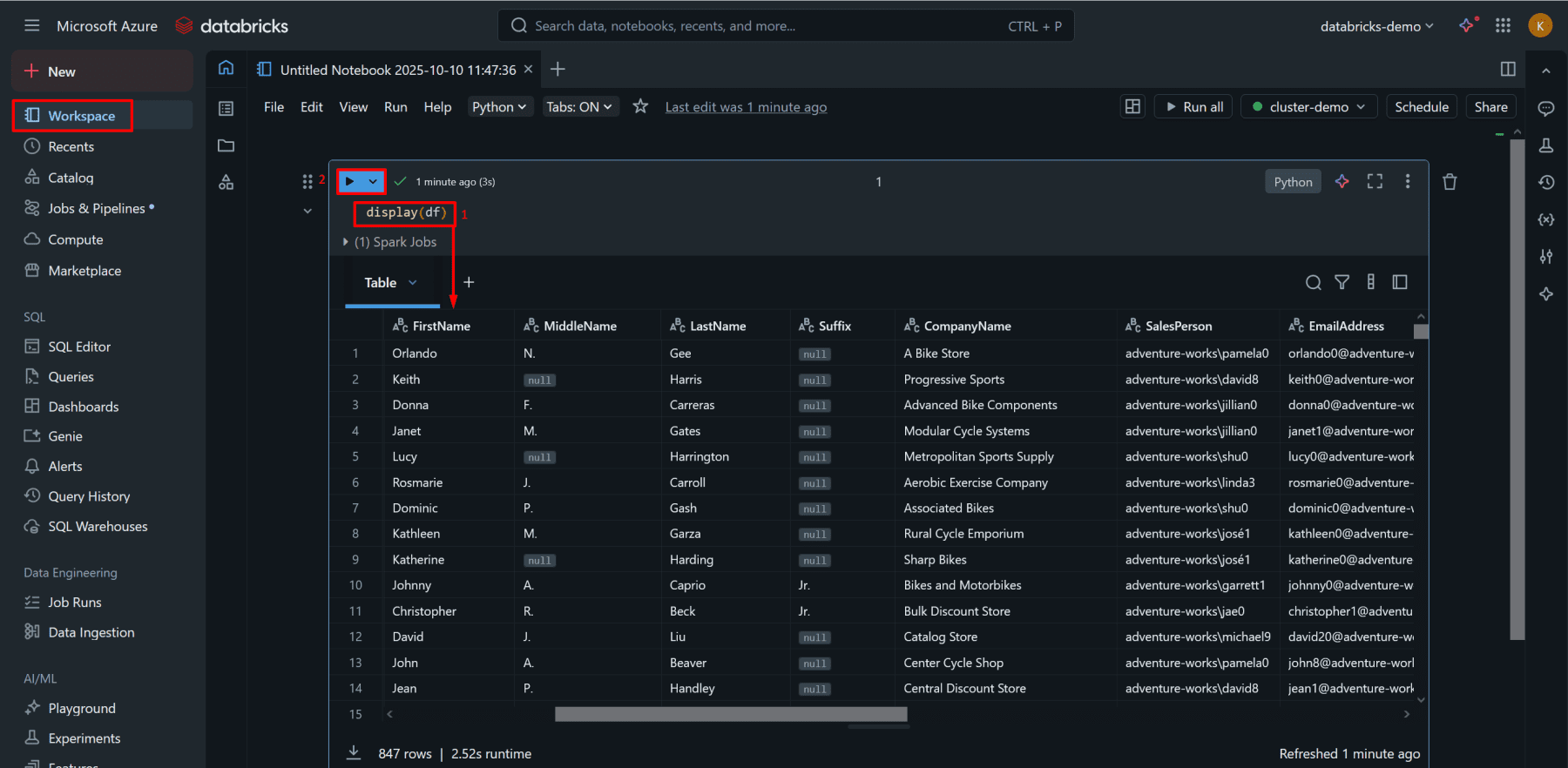
8. Transform Data in Databricks.
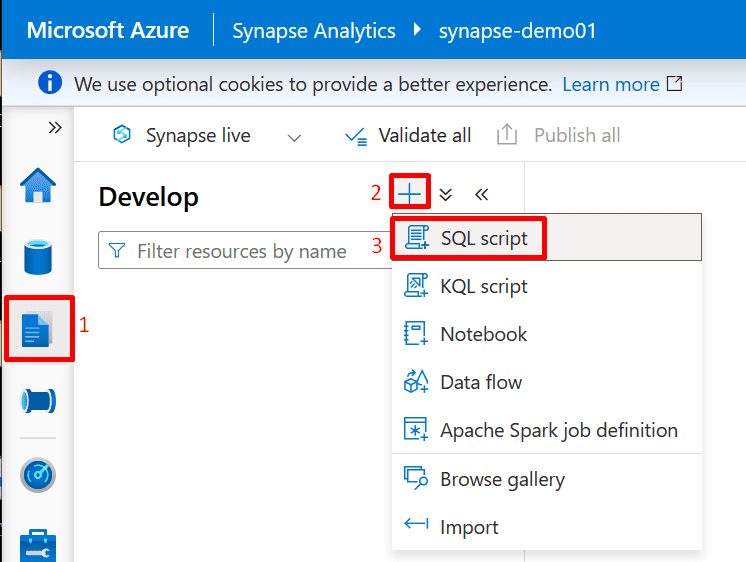
9. Create an Azure Synapse Analytics Workspace.
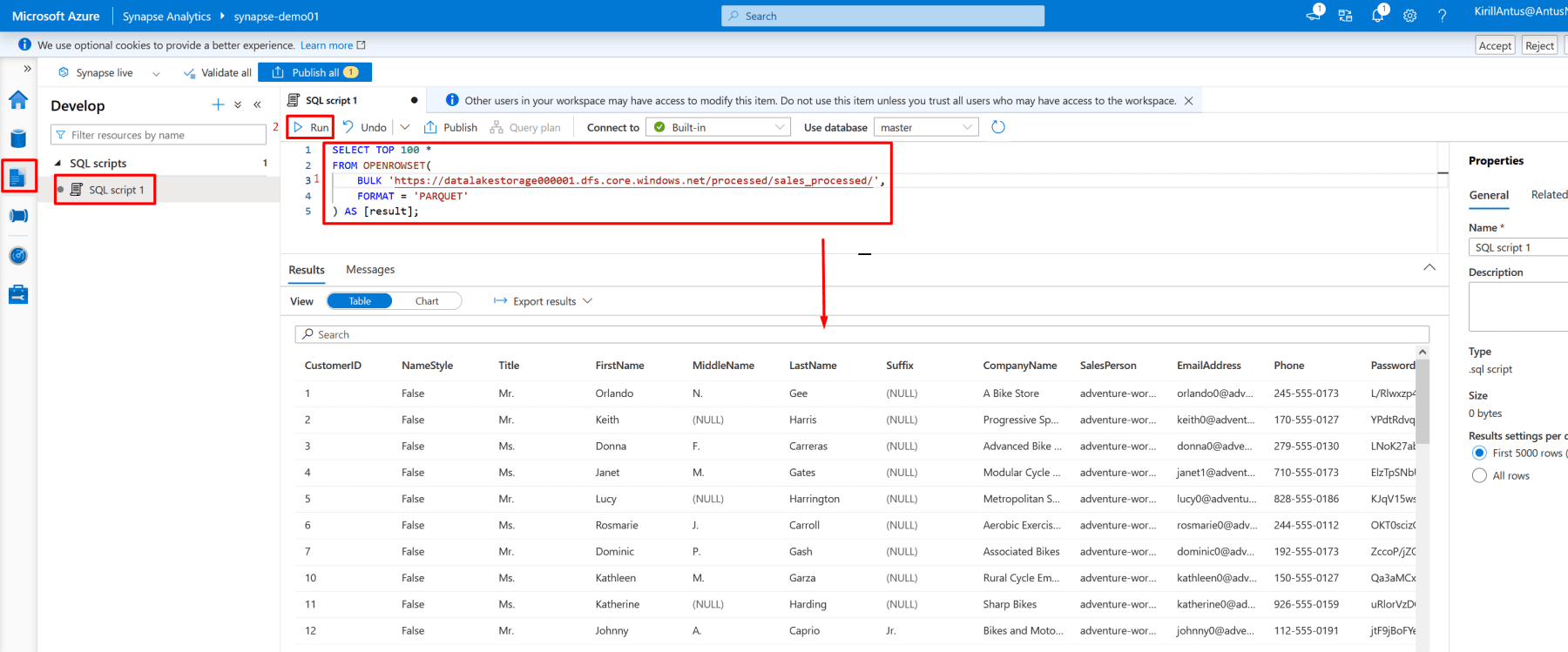
10. Query Processed Data in Synapse
*
Architecture Flow
Raw Data → Data Factory → ADLS → Databricks (Transform) → ADLS (Processed) → Synapse SQL (Query)
Steps
Create a Resource Group.
1. Go to the Azure Portal → Resource groups → Create.
2. Enter a name, e.g., DatabricksRG.
3. Choose a region (e.g., East US).
4. Click Review + Create → Create.

*
Create Azure Data Lake Storage Gen2.
1. Go to Storage Accounts → Create.

*
2. In the Basics tab enter:
- Name: datalakestorage001
- Region: same as the resource group
- Performance: Standard
- Redundancy: LRS

*
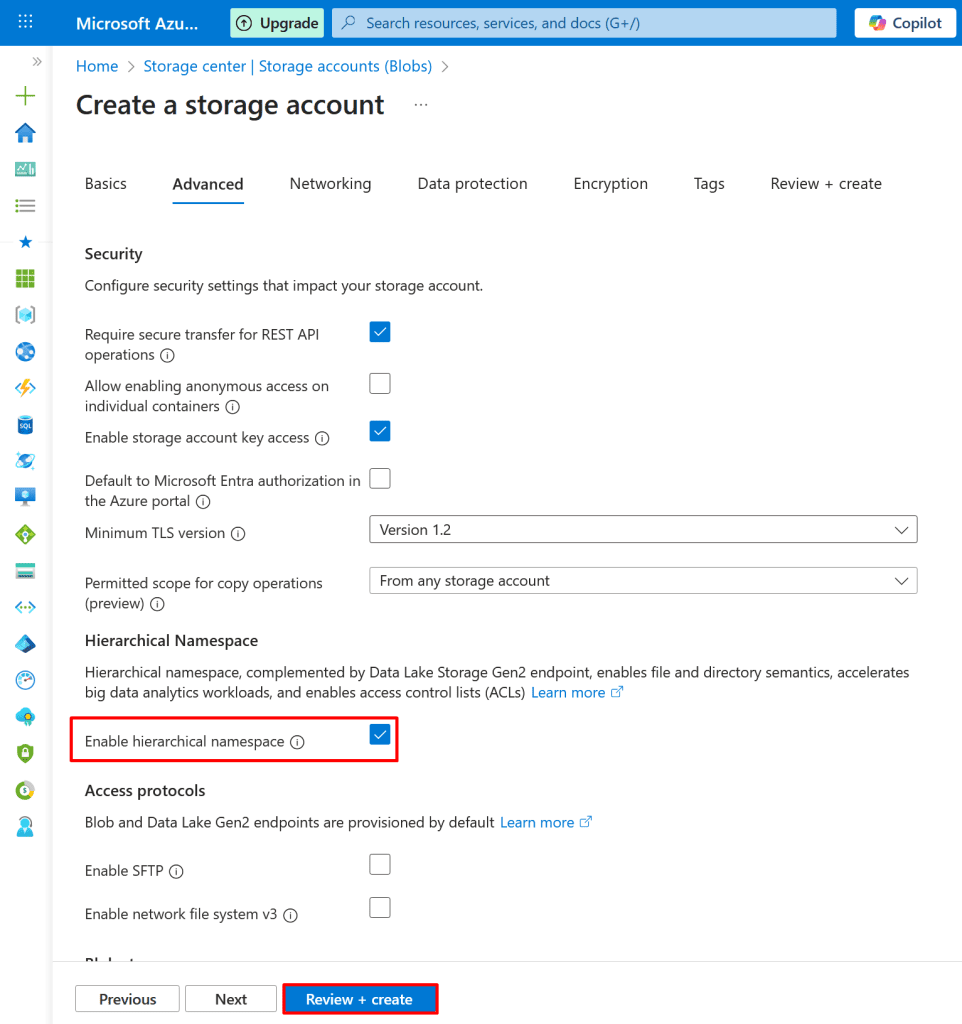
3. Under Advanced → Data Lake Storage Gen2, enable:
- Hierarchical namespace
Click Review + Create → Create.
*
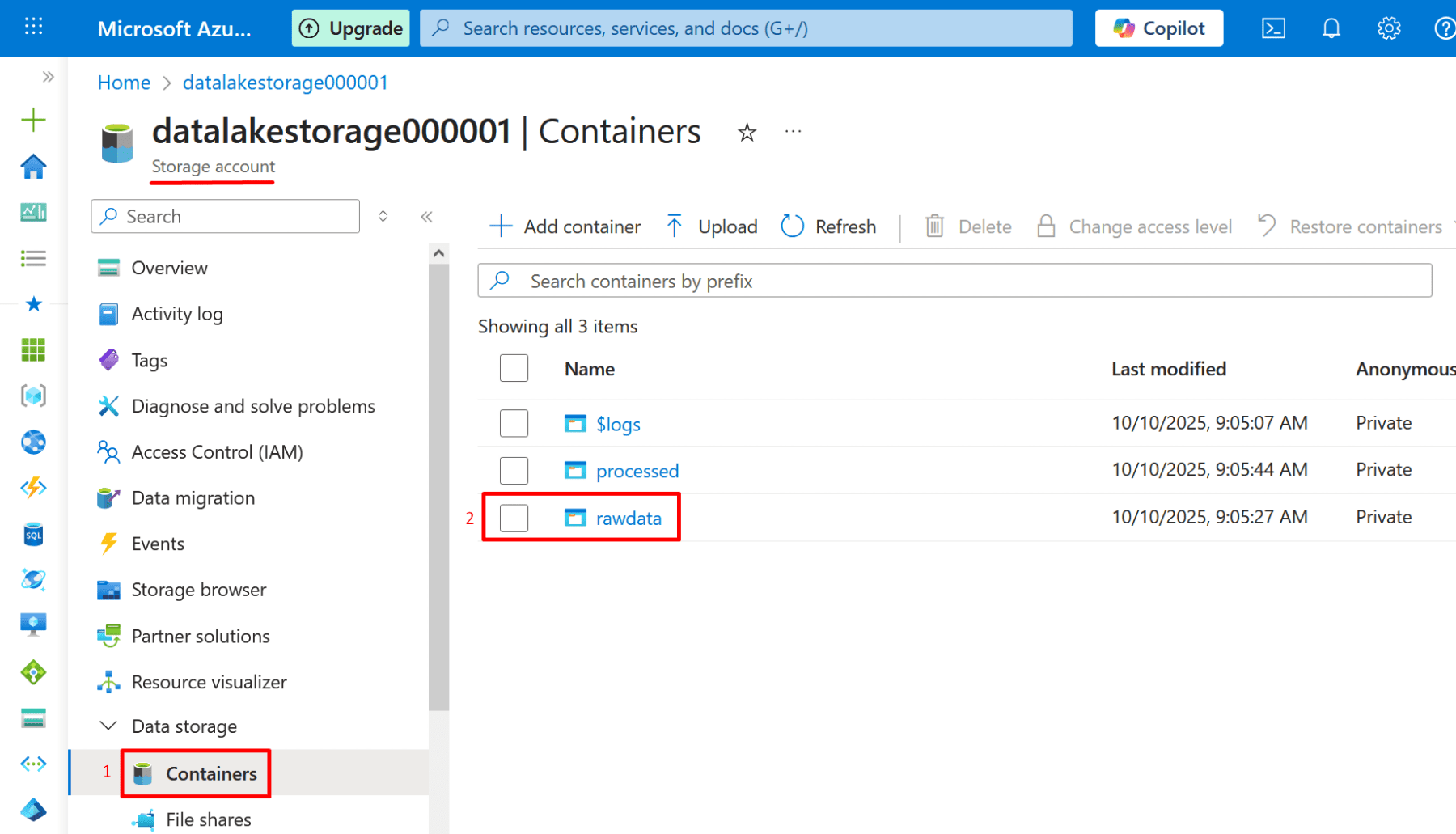
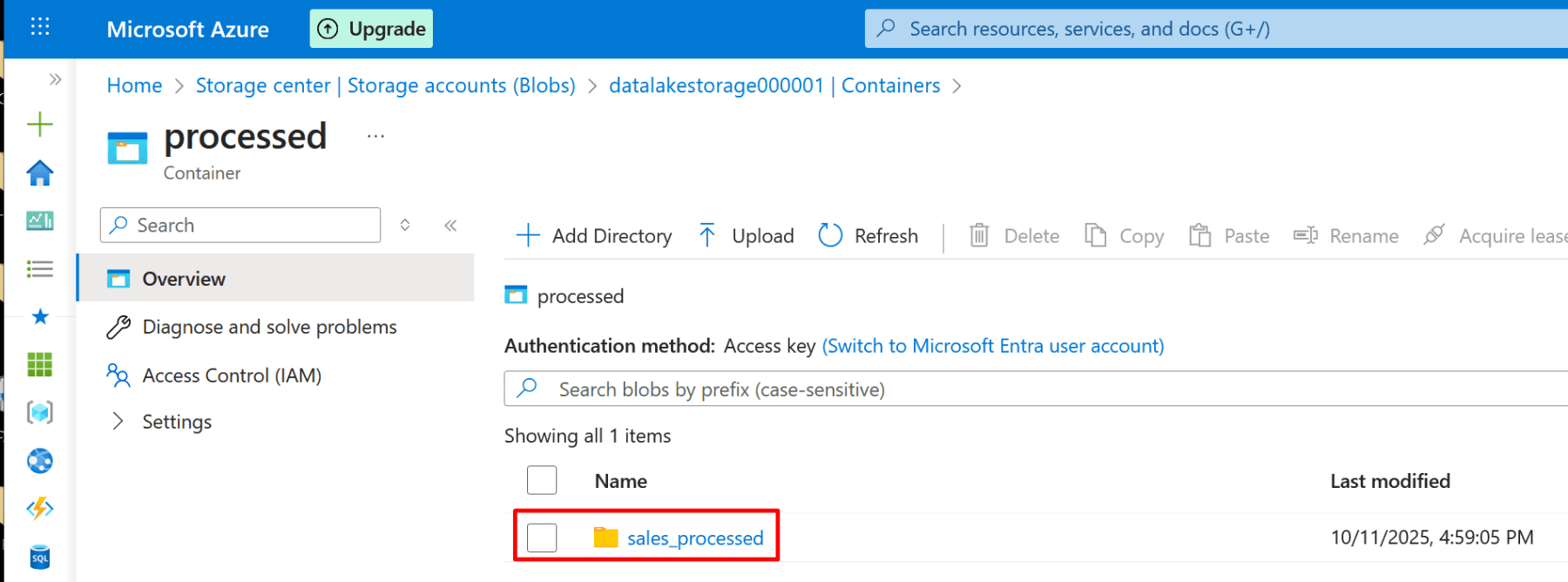
4. After deployment, open the storage account → Containers:
Create a container named rawdata.
- Click Add container.
- Give container name.
- Click create.

*
5. Create another container named processed.
- Click Add container.
- Give container name.
- Click create.

*
Create Azure Databricks Workspace.
1. In the portal, search Azure Databricks → Create.

*
2. In Basics tab configure:
- Workspace name: databricks-demo
- Pricing tier: Standard (or Premium if available)
- Region: same as storage account
- Resource group: use the same one (DatabricksRG)
Click Review + Create → Create.
Note: Databricks will perform data transformation and ETL/ELT operations on data stored in ADLS.
Note: Managed identity is automatically created when creating a Databricks workspace.

*
Create and Configure Databricks Cluster and notebook.
1. Go to your Databricks workspace → Launch Workspace.

*
2. In Databricks Studio → Compute → Create new compute (cluster).
- Name: cluster-demo
- Cluster mode: You can choose Single Node (for demo)
- Click Create

*
3. You must wait until the compute (cluster) status is “Running.”

*
Create a notebook.
A Databricks notebook is an interactive workspace where you can write, run, and visualize code - typically in Python, SQL, Scala, or R - for data analysis, ETL, and machine learning.
Note: Make sure Databricks is in a running state.
1. In Databricks → Workspace → Create Notebook.

*
2. Attach the notebook to the cluster you created.

*
3. Confirm the switch of resources.

*
4. Make sure the notebook is attached to the cluster you created.
*
4. Confirm the language is Python.
Verify the Spark version by running: spark.version